Simple DL Part 3: Features
January, 2021
TLDR
- Features are the baseline input data to our model.
- Models will cheat if they can. We need to be careful about our data as a result.
- More data is always better, but it can be hard to get and use.
Thinking about Features
A deep neural network takes in some piece of data represented as an embedding (i.e. a list of numbers). It passes the data through a stack of transformations, each of which produces an intermediate embedding. And then the model outputs some final embedding, depending on what the task is.

It's embeddings all the way down.
I think of input features as the 0th layer embedding, the foundational embedding that all other embeddings build on (or remove from). The input will often be a super high dimension compared to the rest of the model embeddings, because it is the most full representation of our data (noise and all). The model's job is to take this super high dimensional embedding, and whittle it down to something useful.
In more practical terms, the features are the input data transformed into a numeric representation. Images are generally represented as RGB matrices. Sentences/words/categorical values are often represented as one-hot or multi-hot vectors. And singleton features (e.g. price, date, location, etc.) are generally represented as raw floats.
Feature Preprocessing
We often preprocess that data before feeding it into the model. Generally we transform our data using different kinds of scaling methods, like dividing all of the data by the average of the dataset. This is to make sure all of the inputs are roughly along the same scale -- between -1 and 1, ideally (we'll talk about this a bit more in the tips and tricks section down the line).
A quick mention: if we're working on images, we often want to 'augment' our inputs. We can do that by rotating the images, scaling them all sorts of ways, changing the brightness, contrast, coloring, etc.

An example of image augmentation. Homework question 1: why do we do this?
Models Cheat
Part of what makes models hard to reason about is that models will 'cheat' if they can. If a model has an easy way to minimize the loss, it will take it. Let's say we wanted to train a model to identify cats and dogs. If we only feed in images of cats during training, our model will never figure out how to predict dogs.
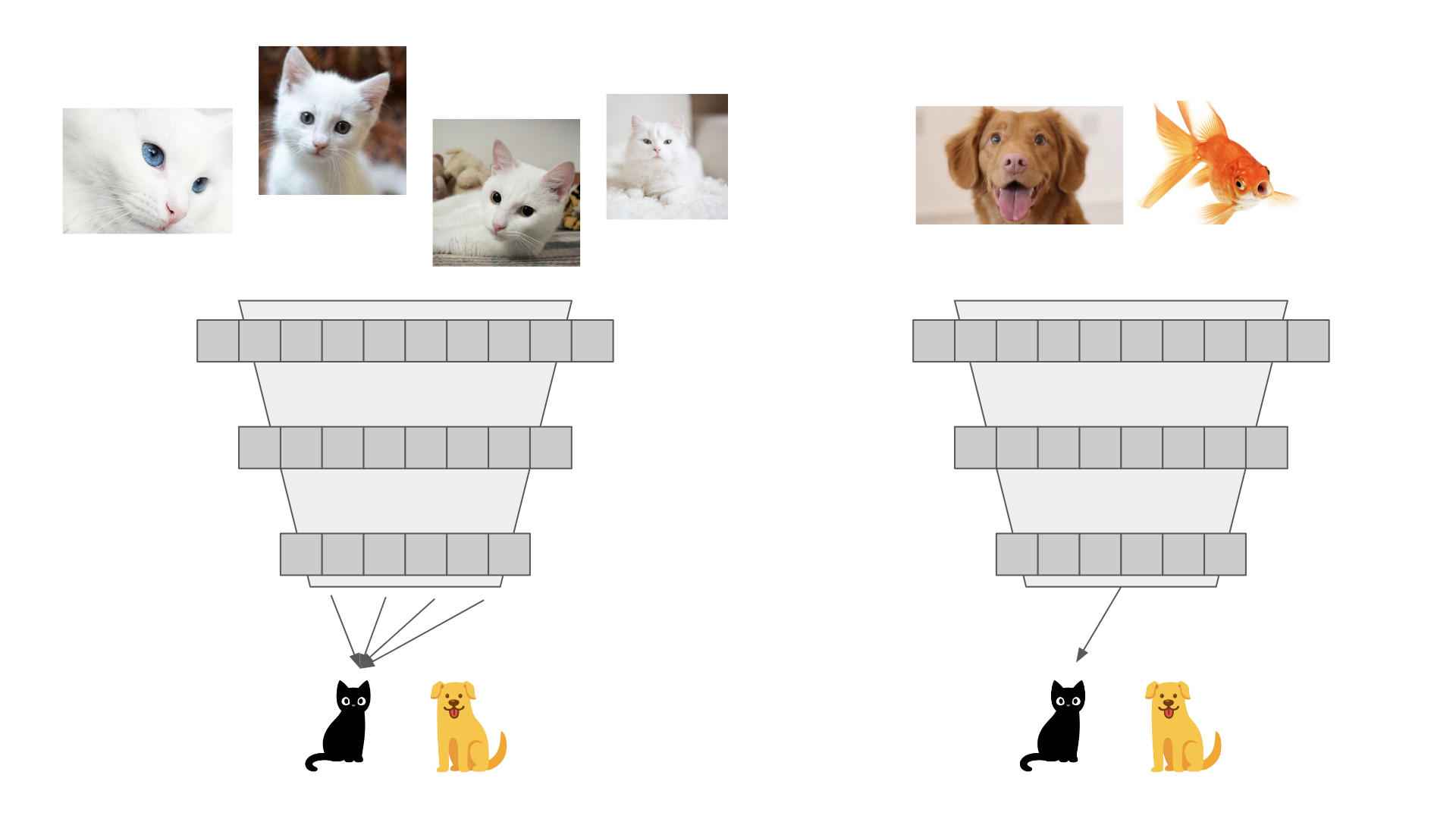
If we only use images of cats during training, the model will 'cheat'. It will learn to ignore all of the input features -- no matter what you put in, it will predict cat.
So let's just include some dogs in our training set, right? It's not that simple. Even in this straightforward case, we have to make sure the dog/cat ratio is roughly even -- after all, if we have 1 dog for 99 cats, the model will still just predict 'cat' every time. More generally, if we accidentally have correlations in our data that let the model minimize the loss, the model will use it. So we not only have to make sure the ratios are good, we also need to make sure there aren't hidden relationships in size, shape, color, or anything else.
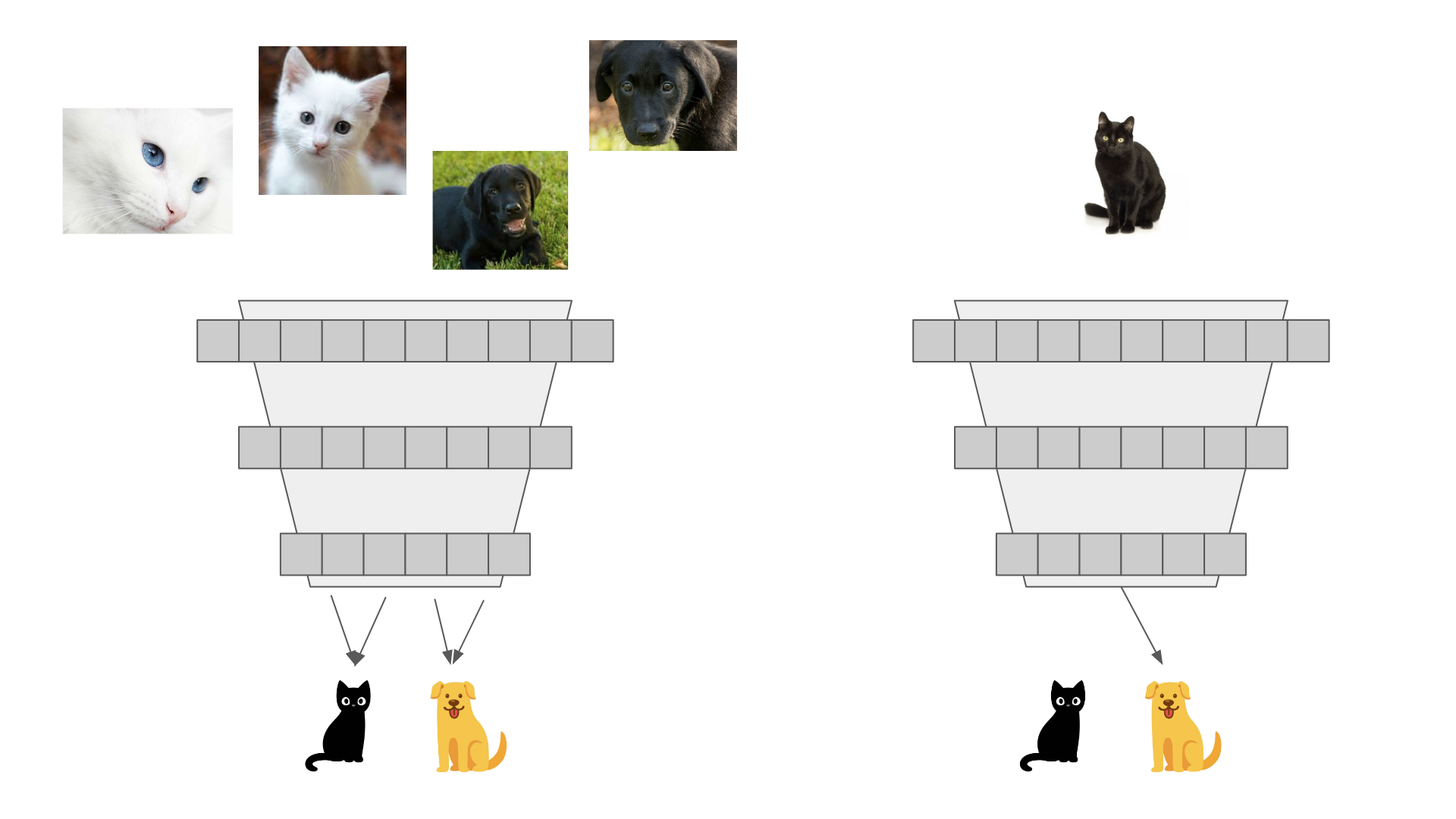
If we only train on white cats and black dogs, the model isn't going to learn anything about cats and dogs. It's only going to learn about color. If the model sees a black cat, it will predict 'dog'. And if it sees a white dog, it'll predict 'cat'. This is why we augment our input features.
This is why we have to care about the input features. Data matters, whether we're training a pet identifier or a tank detector. As a general rule of thumb, more data is better. The more training data we have, the better the input will match the true data distributions, and the better our model will perform. And, the more varied our input data features are, the more baseline information the model has to work with, and the better the underlying embeddings will be.
So just throw more data at it, right?
In a sense, yes, actually. A lot of the big problems in deep learning are really data acquisition problems. If you have a good source of data that correlates well with the problem you're trying to solve, you're probably 80% of the way to getting good embeddings, which in turn is 90% of solving a deep learning problem.
But it's not that easy. There's always a catch. I work at Google, which arguably has the most data access in the world, and even in my day job we struggle with getting data, cleaning it, labeling it, and ensuring it works for our problem space. Overall, accessing more data is hard. And at a large enough scale, it's super inefficient. We'll talk a bit more in future sections about what else we can do when we can't get more data.
Conclusion
Features are the foundation of every ML model. Your model can only be as good as the input features, because the input features are an upper limit on the quality of the information available. Shit goes in, shit comes out. But ML models really want to succeed, and they can find all sorts of correlations in the data that may not be obvious even to an expert. So more data -- both in quantity and in quality -- is always better. If you only have a fixed budget, and aren't sure how to spend it, improving your data access and cleaning pipelines is a guaranteed way to get some bang for your buck. After all, your data is the foundation for everything else.
Homework Answers
- Image augmentation -- and data augmentation in general -- is used to increase the functional size of the dataset and make the model invariant to common changes in the data. This makes the training dataset more reflective of real world data, and helps avoid issues with tank detection. Note that there is no such thing as a free lunch: if you augment your data, your model capacity needs to increase as well.