Programming: Write Patterns
October, 2021
People Learn Through Pattern Matching
The best way to get someone to understand something is through repetition.
This is hopefully uncontroversial. Instrumentalists will repeat scales over and over until the scales are 'in their fingers'. Children will practice writing the same letters repeatedly, tracing out letters in size 50 font in little handbooks. Slightly older children practice multiplication tables until they are second nature. Every language in the world has some version of the phrase 'practice makes perfect'. Speechwriters and self-help leadership books both proclaim that you must over repeat yourself to get an idea across. And adults in our particular field like to cite the 10000 hour rule.
There is probably some interesting synaptogenesis happening between neural circuits that allows us to connect directly to our long term memory, making recall easier. Whoever figures that out is going to be a Nobel Prize winner/billionaire. But in the meantime I don't particularly care why people understand better through repetition. I just take it as granted that pattern recognition is a thing.
Legibility is Really Important
One of the most important differences between a junior and a senior programmer is that the former writes code for himself, and the latter writes code for everyone else. When I think about code from programmers I respect, it is invariably well documented, with variables that have reasonable names and consistent stylistic practices. All of these extra bells and whistles are designed to make code legible for people who don't have the luxury of reaching into the short term memory of the writer, at the moment of writing. And in many ways, this practice is self serving: any engineer worth a damn knows that they will need to go back to his/her own code, sometimes months or years later. So I hope it's also uncontroversial when I say that having legible code is really really important.
Patterns Help Legibility
Here are a few other examples of techniques used to improve legibility:
- legible code is stylistically consistent: it uses the same spacing (2 spaces vs 4 spaces), variable naming pattern (snakecase vs camelcase), bracket convention (same line, differing lines), imports come at the top, etc. etc.
- legible code has variable and function names that accurately describe what the variable is/what the function does, allowing readers to use context from the outside world to infer behavior.
- legible code has well defined data structures. Complex nested objects are documented and used in the same way repeatedly. The types of any variable are (ideally) always obvious.
- legible code tends to follow a single paradigm. Paradigms are a meta abstraction over programming -- paradigms don't deal with what code does, but rather how code should be structured. Paradigms exist to fit different styles of programming into boxes to make them easier to understand. They are, fundamentally, a collection of patterns that people use to mentally model their code.
- legible code is written in one language. Generally speaking, there is a massive increase in comprehension overhead when a codebase begins to mix programming languages. Depending on the team, adding a new language to the stack may be a bad idea even when the new language solves a unique problem. This also applies to libraries/frameworks that basically act as new languages (e.g. React).
These considerations are all meta -- they aren't about what the code does, but rather how the code should be written. You could solve any programming problem without these constraints. However, code that follows the above constraints is better because it reduces the cognitive load of the future reader/maintainer by using pattern matching and repetition as an efficiency hack.
Other Benefits of Patterns
Purposely creating and following patterns has a lot of really nice side effects beyond future legibility.
Extending code that follows a specific pattern is easy, because you can copy-paste. For example, imagine a CRUD server system architecture that follows a validate-process-store pattern:
def post_foo(request):
foo = validate(request.json())
processed_foo = process_foo(foo)
stored_foo = database.store(processed_foo)
return stored_foo
def post_bar(request):
bar = validate(request.json())
processed_bar = process_bar(bar)
stored_bar = database.store(processed_bar)
return stored_bar
Any newcomer to the codebase only needs to learn how one of these post functions work to understand all future ones. And, adding a new object, baz, is as easy as copy pasting any of the previous functions.
Catching bugs is much easier in a highly patterned codebase, because people are almost as good at finding mistakes in a pattern as they are at recognizing patterns themselves. For example, imagine a series of functions that all take (mostly) the same parameters:
def foo(apple, cherry, counter):
pass
def bar(apple, cherry, time):
pass
def baz(apple, cherry, sandwich_ingredients):
pass
...
foo('apple', 'cherry', 0)
bar('apple', 'cherry', time.time())
baz('apple', 'cherry', ['bread', 'meat', 'bread'])
Here, it is easy to quickly check if the function calls are correct because we know they all start with the same parameters in the same order. If we varied the parameters in each function randomly:
def foo(cherry, counter, apple):
pass
def bar(cherry, apple, time):
pass
def baz(apple, sandwich_ingredients, cherry):
pass
...
foo('cherry', 0, 'apple')
bar(time.time(), 'apple', 'cherry')
baz('apple', ['bread', 'meat', 'bread'], 'cherry')
then the bug I purposely introduced above may not be so easy to find on review.
Understanding APIs and Interfaces is much easier when code is written following a consistent pattern. More than anything else, the best APIs are predictable -- that is, given similar inputs, similar endpoints will do similar things. Take a look at the Stripe API. It follows RESTful patterns. Almost every object can be accessed with a GET with an :id path. Almost every object is returned with the object name (always in snakecase) and an id. This kind of consistency can be found everywhere in the API. Together, it makes building applications on top of the Stripe API really easy -- if you know how to POST a charge, you've figured out 90% of how to POST a customer, or a refund, or a payout, or anything else.
Thinking About System Patterns
I tend to be a bit of a stickler about patterning. I personally think conscious choices about pattern matching should be done at every level of the code base, from variable naming to import ordering. But as long as system level patterns are well thought out, I can compromise on everything else.
A system level pattern is a meta constraint that makes state manipulation a set of consistent steps to translate from one part of the system to the next. System patterns encompass APIs and interfaces, but in my mind cover a broader spectrum of programming behavior. The validate-process-store pattern described above is a very basic form of system pattern.
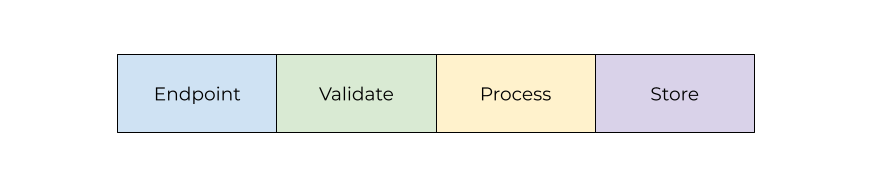
We can get more specific. For example, we can define where the validation parameters come from. Or we could define where the processing code lives. Or we could introduce additional validation steps before storage. Or we could enforce a specific form of error handling, such as using Status monads. Every additional patterned step makes the process of adding more code easier.
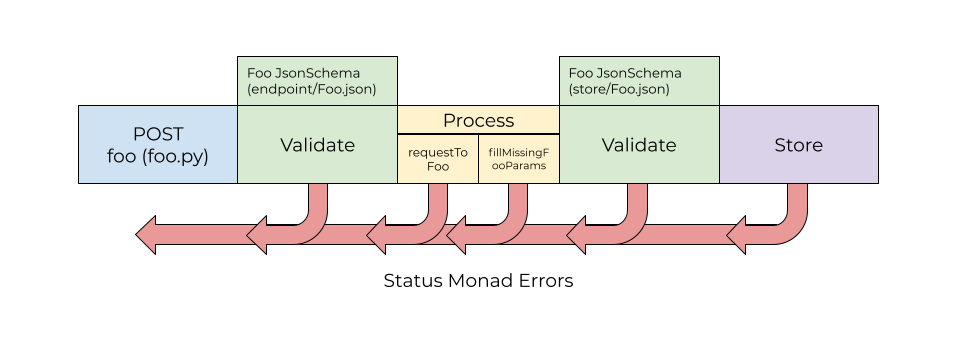
At this point, adding a new tracked object to this codebase is easy. Like a madlibs, we know exactly what spaces need to be filled in, with what type of code. All that's left is filling in the gaps.
Closing Thoughts
I think most pattern planning can and should be done in the design stage. Most of my design docs are wrapped up in what the right 'pattern' should be, almost to the exclusion of everything else. Even though I generally work on backend, this is a foundational design/ux exercise -- when choosing patterns, I need to be aware of who is using my code, and for what purpose.
And it pays off surprisingly well. Though it may not be obvious, code that is well patterned often has fewer spaghetti dependencies, which in turn allows for faster iteration times for feature development and more flexibility for different use cases.
A while ago, I saw a comment on HN that I really liked. It went something like this:
Dependencies (coupling) is an important concern to address, but it's
only 1 of 4 criteria that I consider and it's not the most important
one. I try to optimize my code around reducing state, coupling,
complexity and code, in that order. I'm willing to add increased
coupling if it makes my code more stateless. I'm willing to make it
more complex if it reduces coupling. And I'm willing to duplicate code
if it makes the code less complex. Only if it doesn't increase state,
coupling or complexity do I dedup code.
I would add patterning in between complexity and coupling. That is, I will try to reduce state, reduce coupling, maintain patterns, decrease complexity, and reduce code duplication. If maintaining a pattern results in increased complexity or duplicated code, I would take that trade.