Neural Network Sentience
Written June, 2022. Published October, 2022.
LaMDA
Recently an engineer at my previous place of work publicly claimed that a chatbot codenamed LaMDA had achieved sentience. The engineer was fired, largely because he had reached out to federal representatives demanding more scrutiny on his employers.
The ensuing media coverage has brought AI ethics to the forefront. Many very smart people have questioned whether existing technology is even sufficient for 'sentience'. I think neural networks like LaMDA -- which I believe are architecturally similar to GPT-3 -- are unlikely to be sentient. Even though LaMDA produces realistic conversation, the model has distinct 'training' and 'inference' stages, which prevent it from 'learning' new concepts or retaining memory.
But this got me thinking about systems that, if they displayed the same conversational richness, would be much harder for me to dismiss as purely mechanical. Systems that explicitly store memory and react to new information. Systems that could plausibly learn a sense of 'self'. Is it possible to design such a system using technology that currently exists?
Three Neural Nets and a Database
Consider a system composed of three neural nets and an embedding database.
The first NN is a large scale language model that ingests text and produces embeddings (eg. CLIP). Its job is to create a latent representation of the world. In theory this could be an entirely pretrained, frozen model -- the important piece is that the output embeddings are semantically coherent.
The second NN is a transformer model which produces a variable sequence of embeddings that in turn act as keys to the embedding database. The second NN ingests the output of the first NN, as well as a kNN query of the embedding database. This allows the second NN to learn how to 'attend' based on previous information, thereby refining it's ability to pull up other relevant data.
The embedding database is a straightforward indexable collection of embeddings, like FAISS. The embedding database is seeded with a pre-embedded corpus of data. That data could be anything -- a collection of facts about the world, 'I' statements about the model, etc. During the system runtime, every embedding produced by the first NN is stored in the database. As a result, the 'working memory' of the system should grow to account for new input information.
The third NN is another large language model, which produces text outputs from embeddings. This model is essentially a decoder -- its job is to turn input embeddings into human language. It ingests input embedding from the first NN and the embeddings queried by the second NN from the database, and produces output text. The output text is immediately fed back into the system for one cycle, so that the response is recorded in the embedding database (possibly with the added context 'attached' somehow).
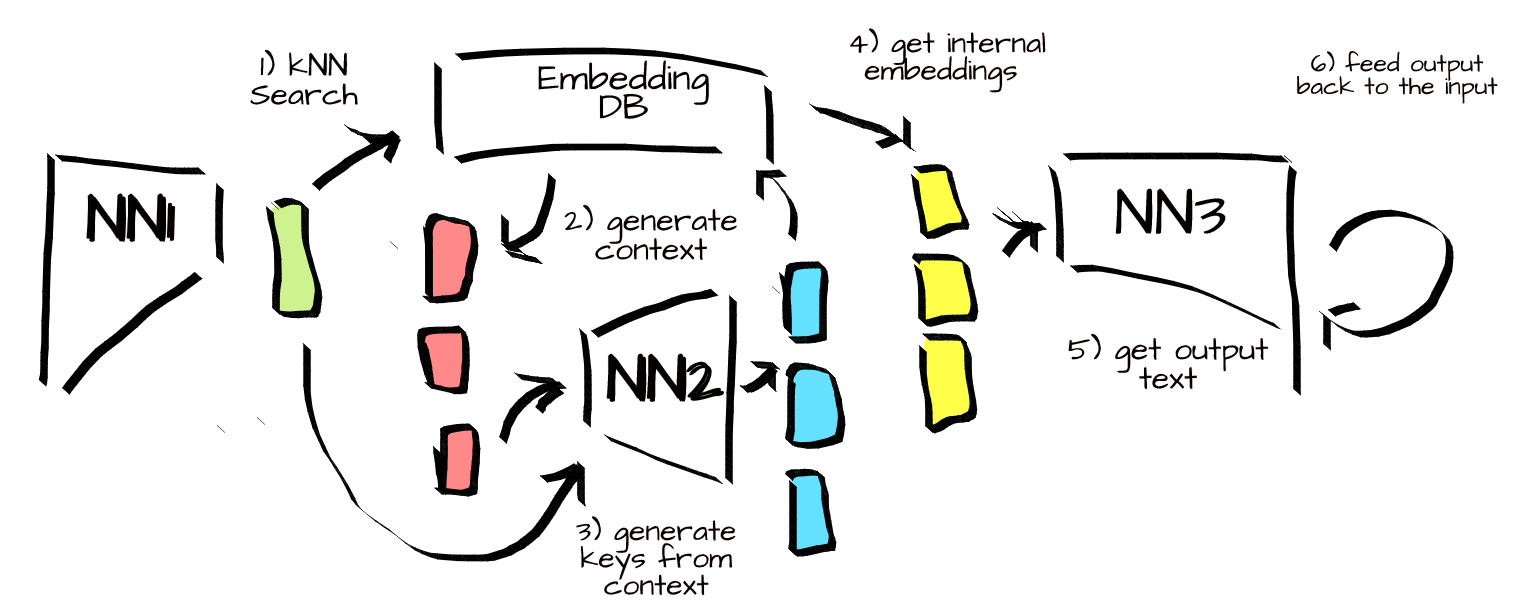
This system is a fairly straightforward modification of Deepmind's RETRO -- the two main changes are that the proposed system continually adds new data to the database, including its own outputs; and it uses a NN on top of a kNN to do retreival of previous data. This system is end to end differentiable, and could be trained on any of the token-prediction tasks that have proven so effective.
Is it sentient?
I have no idea. 'Sentience', like 'conscious', feels hard to define, and I don't want to spend the words to do so here. Suffice to say, for me personally, I think I would have trouble distinguishing the system above from a 'sentient' one. Let's walk through a few tasks.
The system should be able to learn new concepts. Let's say we want to teach the system about a new word, 'foo'. We can explicitly feed the model new 'facts' about the word 'foo', which will result in the model storing those 'facts' in the DB. The next time we call something related to foo, the kNN will kick in and grab other related 'foo' facts, all of which are points in the underlying metric space. These will all be fed to the second NN, which can create a coherent picture of which 'foo' facts are relevant, and output those to the decoder.
The system should, as a corollary to the above, be able to learn about itself. We can feed the system statements about itself that can be referenced in the same way as 'foo' above. These self-descriptions can then be used to color queries about itself. We can go further. During the kNN lookup stage for every query, we can actually run two kNNs -- one for the prompt, and one for some query that returns embeddings related to the model's 'personality'. This would allow the system's understanding of itself to come through on all outputs.
In theory, the system should be able to 'think' without further prompting. This can be done by continually looping the output to the input, instead of only doing it for one pass. Over time the system should build up a corpus of its own 'thoughts'. (I strongly suspect this will mostly output gibberish, as the system goes off the rails due to some weird non-equillibrium point in the embedding space. NaNs everywhere. BUT NaNs are a question of empirics, and obviously I'm not concerning myself with that here)
I'd love to talk this through with other folks who know a bit more than I do about deep learning, in case there's something obvious I'm missing about why the above is impossible or won't do what I think it will. But overall, I'm as skeptical of people who say sentient AI can never happen, as I am of those who say it has already occurred. It seems obvious to me that the technology available to us is quite strong, given the right capital allocation (and a lot of grad-student time).